Synthetic Document Benchmark
Measuring NER accuracy on programmatically generated documents with pixel-perfect ground truth.
Project Overview
Pixel-perfect synthetic documents (invoices, tax forms, medical records, legal pleadings, etc.) with exact bounding boxes and entity labels for every field on the page.
Entity Types
Every annotation is labeled with one of 19 entity types across two categories. Standard NER types represent extractable information — names, dates, amounts, identifiers — the targets for NER model evaluation. Structural types describe document layout elements like table cells and section headings.
Standard NER
PERSON
ORG
DATE
ADDRESS
AMOUNT
PHONE
ID
EMAIL
LOCATION
QUANTITY
URL
DURATION
Structural
TABLE_CELL
TABLE_HEADER
FIELD_LABEL
TITLE
SECTION_TITLE
TEXT
CAPTION
Dataset
Current
SDD-Nano
401 docs
781 pages
45K annotations
101 templates · ~4 docs/template · 19 entity types
Planned
SDD-Small
1K docs
~2K pages
~114K annotations
101 templates · ~10 docs/template
Planned
SDD-Medium
10K docs
~19K pages
~1.1M annotations
101 templates · ~99 docs/template
Planned
SDD-Large
100K docs
~195K pages
~11.4M annotations
101 templates · ~990 docs/template
All 257 document templates in the benchmark. Use the toggle to switch views. Click a card label to expand details.
NER Results
Ground Truth
Document
DeepSeek-OCR-2 + Qwen3-8B
Tesseract + spaCy (coming soon)
Tesseract + DeBERTa (coming soon)
Qwen3-VL + Qwen3 (coming soon)
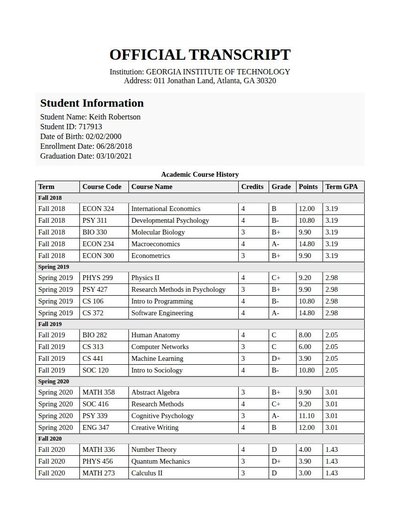
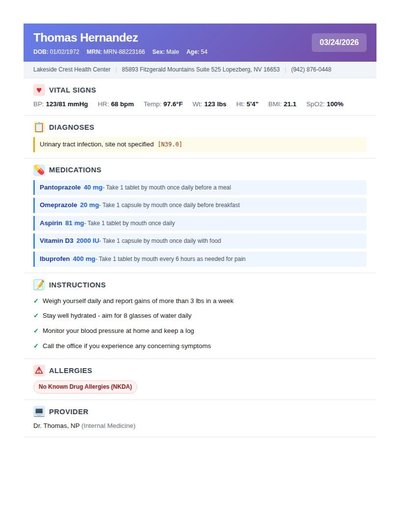
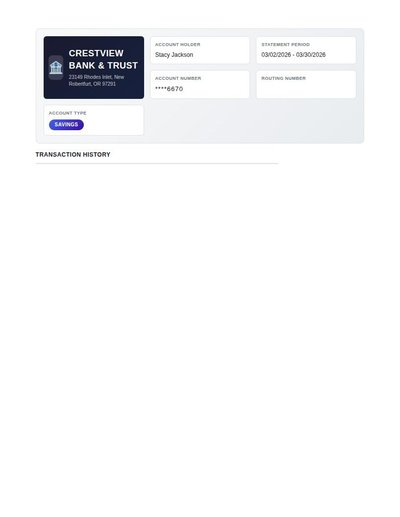
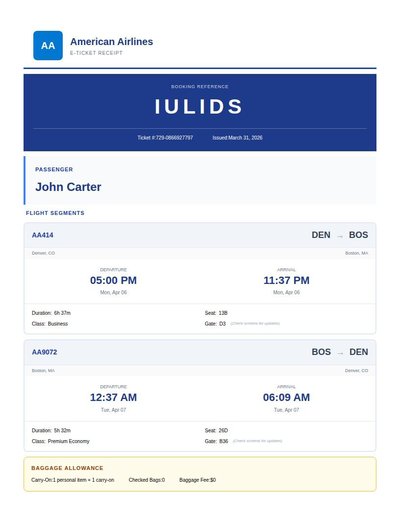
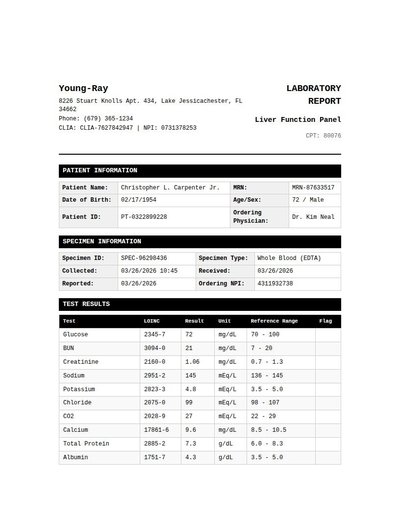
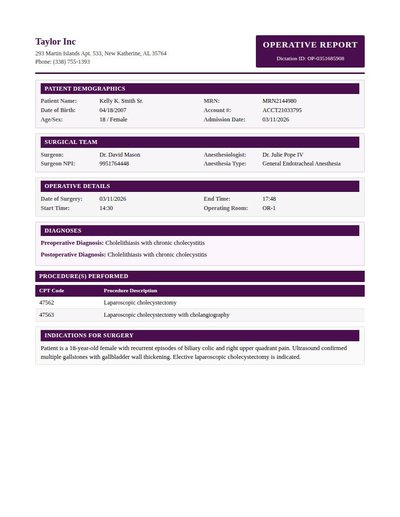
Academic Transcript
225 annotations
Standard entities 240
Docs / Pages 5
Hits 18
Misses 222
Type confusion 0
F1 (approx) 14%
View in Inspector →
Academic Transcript Rev A
61 annotations
Standard entities 170
Docs / Pages 7
Hits 18
Misses 152
Type confusion 0
F1 (approx) 19%
View in Inspector →
Academic Transcript Rev B
200 annotations
Standard entities 162
Docs / Pages 4
Hits 18
Misses 144
Type confusion 0
F1 (approx) 20%
View in Inspector →
Ach Authorization
29 annotations
Standard entities 30
Docs / Pages 4
Hits 18
Misses 12
Type confusion 0
F1 (approx) 75%
View in Inspector →
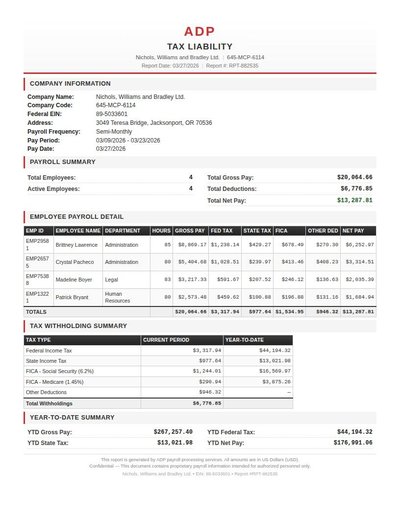
ADP Report
172 annotations
Standard entities 148
Docs / Pages 2
Hits 36
Misses 112
Type confusion 0
F1 (approx) 39%
View in Inspector →
Advance Directive
38 annotations
Standard entities 52
Docs / Pages 6
Hits 40
Misses 12
Type confusion 0
F1 (approx) 87%
View in Inspector →
Affidavit
37 annotations
Standard entities 35
Docs / Pages 4
Hits 21
Misses 14
Type confusion 0
F1 (approx) 75%
View in Inspector →
After Visit Summary
37 annotations
Standard entities 53
Docs / Pages 9
Hits 48
Misses 5
Type confusion 0
F1 (approx) 95%
View in Inspector →
After Visit Summary Rev A
36 annotations
Standard entities 32
Docs / Pages 4
Hits 16
Misses 16
Type confusion 0
F1 (approx) 67%
View in Inspector →
After Visit Summary Rev B
19 annotations
Standard entities 32
Docs / Pages 8
Hits 18
Misses 14
Type confusion 0
F1 (approx) 72%
View in Inspector →
AIA Construction Pay App
210 annotations
Standard entities 161
Docs / Pages 2
Hits 26
Misses 135
Type confusion 0
F1 (approx) 28%
View in Inspector →
AIA G702/G703
72 annotations
Standard entities 246
Docs / Pages 4
Hits 49
Misses 197
Type confusion 0
F1 (approx) 33%
View in Inspector →
Answer To Complaint
17 annotations
Standard entities 30
Docs / Pages 6
Hits 18
Misses 12
Type confusion 0
F1 (approx) 75%
View in Inspector →
Appointment Confirmation
26 annotations
Standard entities 20
Docs / Pages 4
Hits 15
Misses 5
Type confusion 0
F1 (approx) 86%
View in Inspector →
Auto Loan Application
46 annotations
Standard entities 86
Docs / Pages 6
Hits 68
Misses 18
Type confusion 0
F1 (approx) 88%
View in Inspector →
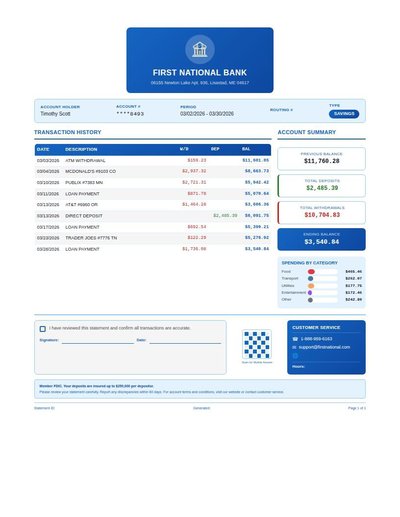
Bank Statement
31 annotations
Standard entities 173
Docs / Pages 4
Hits 77
Misses 96
Type confusion 0
F1 (approx) 62%
View in Inspector →
Bank Statement Rev A
11 annotations
Standard entities 186
Docs / Pages 5
Hits 84
Misses 102
Type confusion 0
F1 (approx) 62%
View in Inspector →
Bank Statement Rev B
137 annotations
Standard entities 132
Docs / Pages 2
Hits 29
Misses 103
Type confusion 0
F1 (approx) 36%
View in Inspector →
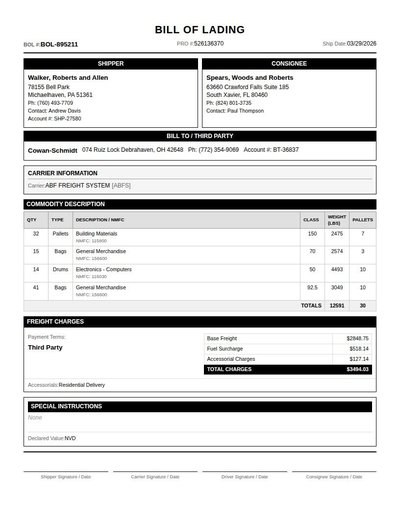
Bill Of Lading
72 annotations
Standard entities 56
Docs / Pages 3
Hits 24
Misses 32
Type confusion 0
F1 (approx) 60%
View in Inspector →
Bill Of Materials
238 annotations
Standard entities 166
Docs / Pages 4
Hits 89
Misses 77
Type confusion 0
F1 (approx) 70%
View in Inspector →
Birth Certificate
59 annotations
Standard entities 38
Docs / Pages 2
Hits 20
Misses 18
Type confusion 0
F1 (approx) 69%
View in Inspector →
Birth Certificate Rev A
0 annotations
Standard entities 76
Docs / Pages 10
Hits 35
Misses 41
Type confusion 0
F1 (approx) 63%
View in Inspector →
Birth Certificate Rev B
48 annotations
Standard entities 34
Docs / Pages 2
Hits 17
Misses 17
Type confusion 0
F1 (approx) 67%
View in Inspector →
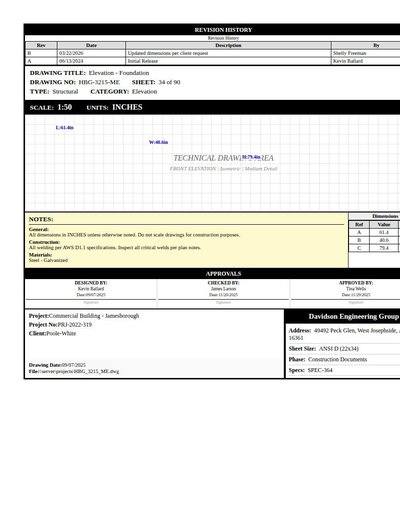
Blueprint Rev A
104 annotations
Standard entities 64
Docs / Pages 2
Hits 14
Misses 50
Type confusion 0
F1 (approx) 36%
View in Inspector →
Blueprint Rev B
100 annotations
Standard entities 60
Docs / Pages 2
Hits 20
Misses 40
Type confusion 0
F1 (approx) 50%
View in Inspector →
Blueprint Technical Drawing
116 annotations
Standard entities 72
Docs / Pages 2
Hits 29
Misses 43
Type confusion 0
F1 (approx) 57%
View in Inspector →
Boarding Pass
35 annotations
Standard entities 41
Docs / Pages 2
Hits 18
Misses 23
Type confusion 0
F1 (approx) 61%
View in Inspector →
Building Permit
53 annotations
Standard entities 64
Docs / Pages 6
Hits 44
Misses 20
Type confusion 0
F1 (approx) 81%
View in Inspector →
Business Card
9 annotations
Standard entities 13
Docs / Pages 2
Hits 9
Misses 4
Type confusion 0
F1 (approx) 82%
View in Inspector →
Business Card Rev A
15 annotations
Standard entities 15
Docs / Pages 2
Hits 7
Misses 8
Type confusion 0
F1 (approx) 64%
View in Inspector →
Business Card Rev B
11 annotations
Standard entities 17
Docs / Pages 2
Hits 10
Misses 7
Type confusion 0
F1 (approx) 74%
View in Inspector →
Business Card Rev C
7 annotations
Standard entities 11
Docs / Pages 2
Hits 4
Misses 7
Type confusion 0
F1 (approx) 53%
View in Inspector →
Business License
33 annotations
Standard entities 36
Docs / Pages 4
Hits 17
Misses 19
Type confusion 0
F1 (approx) 64%
View in Inspector →
Car Rental Agreement
115 annotations
Standard entities 95
Docs / Pages 4
Hits 41
Misses 54
Type confusion 0
F1 (approx) 60%
View in Inspector →
Cease And Desist
24 annotations
Standard entities 46
Docs / Pages 6
Hits 23
Misses 23
Type confusion 0
F1 (approx) 67%
View in Inspector →
Certificate
0 annotations
Standard entities 40
Docs / Pages 10
Hits 32
Misses 8
Type confusion 0
F1 (approx) 89%
View in Inspector →
Certificate Of Analysis
85 annotations
Standard entities 68
Docs / Pages 4
Hits 33
Misses 35
Type confusion 0
F1 (approx) 65%
View in Inspector →
Certificate Rev A
7 annotations
Standard entities 6
Docs / Pages 2
Hits 5
Misses 1
Type confusion 0
F1 (approx) 91%
View in Inspector →
Certificate Rev B
12 annotations
Standard entities 12
Docs / Pages 2
Hits 8
Misses 4
Type confusion 0
F1 (approx) 80%
View in Inspector →
Change Order
37 annotations
Standard entities 85
Docs / Pages 8
Hits 50
Misses 35
Type confusion 0
F1 (approx) 74%
View in Inspector →
Chargeback Dispute
55 annotations
Standard entities 68
Docs / Pages 4
Hits 32
Misses 36
Type confusion 0
F1 (approx) 64%
View in Inspector →
Civil Complaint
19 annotations
Standard entities 42
Docs / Pages 8
Hits 29
Misses 13
Type confusion 0
F1 (approx) 82%
View in Inspector →
Clinical Trial Consent
25 annotations
Standard entities 102
Docs / Pages 19
Hits 37
Misses 65
Type confusion 0
F1 (approx) 53%
View in Inspector →
Closing Disclosure
157 annotations
Standard entities 156
Docs / Pages 4
Hits 88
Misses 68
Type confusion 0
F1 (approx) 72%
View in Inspector →
CMS-1500
129 annotations
Standard entities 67
Docs / Pages 2
Hits 46
Misses 21
Type confusion 0
F1 (approx) 81%
View in Inspector →
CMS-485 Home Health
58 annotations
Standard entities 56
Docs / Pages 8
Hits 37
Misses 19
Type confusion 0
F1 (approx) 80%
View in Inspector →
Collections Notice
39 annotations
Standard entities 58
Docs / Pages 4
Hits 36
Misses 22
Type confusion 0
F1 (approx) 77%
View in Inspector →
Commercial Invoice
116 annotations
Standard entities 81
Docs / Pages 2
Hits 28
Misses 53
Type confusion 0
F1 (approx) 51%
View in Inspector →
Commercial Invoice Rev A
128 annotations
Standard entities 82
Docs / Pages 2
Hits 28
Misses 54
Type confusion 0
F1 (approx) 51%
View in Inspector →
Commercial Invoice Rev B
73 annotations
Standard entities 66
Docs / Pages 2
Hits 37
Misses 29
Type confusion 0
F1 (approx) 72%
View in Inspector →
Commercial Rent Roll
127 annotations
Standard entities 129
Docs / Pages 4
Hits 92
Misses 37
Type confusion 0
F1 (approx) 83%
View in Inspector →
Concealed Carry Permit
18 annotations
Standard entities 22
Docs / Pages 2
Hits 14
Misses 8
Type confusion 0
F1 (approx) 78%
View in Inspector →
Conference Registration
30 annotations
Standard entities 52
Docs / Pages 6
Hits 16
Misses 36
Type confusion 0
F1 (approx) 47%
View in Inspector →
Corporate Resolution
30 annotations
Standard entities 40
Docs / Pages 6
Hits 22
Misses 18
Type confusion 0
F1 (approx) 71%
View in Inspector →
Court Order
18 annotations
Standard entities 40
Docs / Pages 6
Hits 28
Misses 12
Type confusion 0
F1 (approx) 82%
View in Inspector →
Credit Application
99 annotations
Standard entities 80
Docs / Pages 4
Hits 35
Misses 45
Type confusion 0
F1 (approx) 61%
View in Inspector →
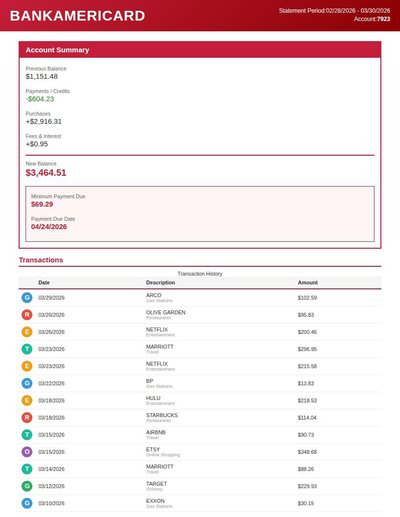
Credit Card Statement
168 annotations
Standard entities 236
Docs / Pages 3
Hits 54
Misses 182
Type confusion 0
F1 (approx) 37%
View in Inspector →
Credit Card Statement Rev A
157 annotations
Standard entities 266
Docs / Pages 4
Hits 74
Misses 192
Type confusion 0
F1 (approx) 44%
View in Inspector →
Credit Card Statement Rev B
88 annotations
Standard entities 115
Docs / Pages 4
Hits 26
Misses 89
Type confusion 0
F1 (approx) 37%
View in Inspector →
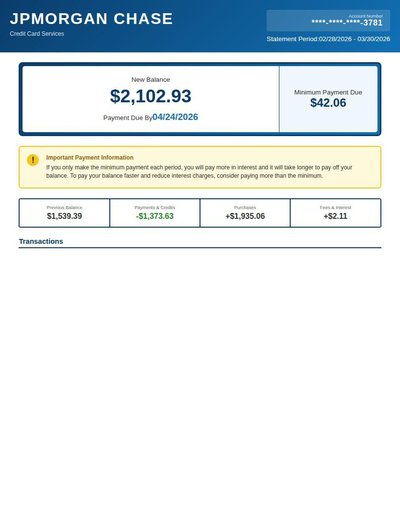
Credit Report
116 annotations
Standard entities 91
Docs / Pages 4
Hits 19
Misses 72
Type confusion 0
F1 (approx) 35%
View in Inspector →
Death Certificate
30 annotations
Standard entities 42
Docs / Pages 4
Hits 30
Misses 12
Type confusion 0
F1 (approx) 83%
View in Inspector →
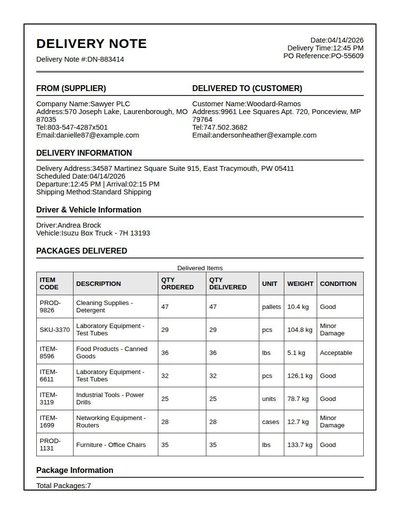
Delivery Note
132 annotations
Standard entities 76
Docs / Pages 4
Hits 26
Misses 50
Type confusion 0
F1 (approx) 51%
View in Inspector →
Demand Letter
30 annotations
Standard entities 64
Docs / Pages 4
Hits 42
Misses 22
Type confusion 0
F1 (approx) 79%
View in Inspector →
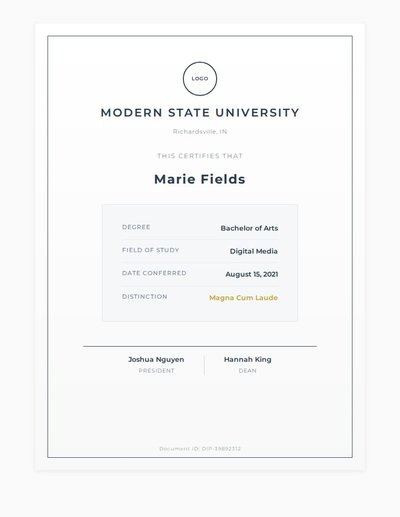
Diploma
15 annotations
Standard entities 14
Docs / Pages 2
Hits 12
Misses 2
Type confusion 0
F1 (approx) 92%
View in Inspector →
Diploma Rev A
11 annotations
Standard entities 14
Docs / Pages 2
Hits 10
Misses 4
Type confusion 0
F1 (approx) 83%
View in Inspector →
Diploma Rev B
10 annotations
Standard entities 14
Docs / Pages 2
Hits 12
Misses 2
Type confusion 0
F1 (approx) 92%
View in Inspector →
Discharge Summary
28 annotations
Standard entities 66
Docs / Pages 6
Hits 22
Misses 44
Type confusion 0
F1 (approx) 50%
View in Inspector →
Divorce Decree
19 annotations
Standard entities 58
Docs / Pages 6
Hits 18
Misses 40
Type confusion 0
F1 (approx) 47%
View in Inspector →
Donation Receipt
54 annotations
Standard entities 47
Docs / Pages 4
Hits 18
Misses 29
Type confusion 0
F1 (approx) 55%
View in Inspector →
Donation Receipt Rev A
21 annotations
Standard entities 34
Docs / Pages 4
Hits 24
Misses 10
Type confusion 0
F1 (approx) 83%
View in Inspector →
Driver License
27 annotations
Standard entities 20
Docs / Pages 2
Hits 12
Misses 8
Type confusion 0
F1 (approx) 75%
View in Inspector →
Driver License Rev A
28 annotations
Standard entities 20
Docs / Pages 2
Hits 13
Misses 7
Type confusion 0
F1 (approx) 79%
View in Inspector →
Driver License Rev B
30 annotations
Standard entities 22
Docs / Pages 2
Hits 12
Misses 10
Type confusion 0
F1 (approx) 71%
View in Inspector →
Driver License Rev C
30 annotations
Standard entities 22
Docs / Pages 2
Hits 14
Misses 8
Type confusion 0
F1 (approx) 78%
View in Inspector →
Easement Agreement
20 annotations
Standard entities 56
Docs / Pages 6
Hits 24
Misses 32
Type confusion 0
F1 (approx) 60%
View in Inspector →
Electric Bill
39 annotations
Standard entities 52
Docs / Pages 4
Hits 35
Misses 17
Type confusion 0
F1 (approx) 80%
View in Inspector →
Employment Agreement
31 annotations
Standard entities 48
Docs / Pages 6
Hits 25
Misses 23
Type confusion 0
F1 (approx) 68%
View in Inspector →
Employment Verification
24 annotations
Standard entities 34
Docs / Pages 4
Hits 24
Misses 10
Type confusion 0
F1 (approx) 83%
View in Inspector →
Eob Detailed
128 annotations
Standard entities 112
Docs / Pages 4
Hits 47
Misses 65
Type confusion 0
F1 (approx) 59%
View in Inspector →
Eob Rev A
17 annotations
Standard entities 79
Docs / Pages 6
Hits 57
Misses 22
Type confusion 0
F1 (approx) 84%
View in Inspector →
Eob Rev B
7 annotations
Standard entities 163
Docs / Pages 8
Hits 39
Misses 124
Type confusion 0
F1 (approx) 39%
View in Inspector →
Event Ticket
45 annotations
Standard entities 32
Docs / Pages 4
Hits 21
Misses 11
Type confusion 0
F1 (approx) 79%
View in Inspector →
Eviction Notice
27 annotations
Standard entities 36
Docs / Pages 4
Hits 26
Misses 10
Type confusion 0
F1 (approx) 84%
View in Inspector →
Eviction Notice Rev A
20 annotations
Standard entities 36
Docs / Pages 6
Hits 22
Misses 14
Type confusion 0
F1 (approx) 76%
View in Inspector →
Eviction Notice Rev B
19 annotations
Standard entities 38
Docs / Pages 6
Hits 28
Misses 10
Type confusion 0
F1 (approx) 85%
View in Inspector →
Explanation Of Benefits
95 annotations
Standard entities 88
Docs / Pages 4
Hits 40
Misses 48
Type confusion 0
F1 (approx) 62%
View in Inspector →
Fax Cover Sheet
46 annotations
Standard entities 26
Docs / Pages 2
Hits 20
Misses 6
Type confusion 0
F1 (approx) 87%
View in Inspector →
Fbar Form
71 annotations
Standard entities 52
Docs / Pages 2
Hits 20
Misses 32
Type confusion 0
F1 (approx) 56%
View in Inspector →
Fictitious Business
24 annotations
Standard entities 26
Docs / Pages 6
Hits 24
Misses 2
Type confusion 0
F1 (approx) 96%
View in Inspector →
Financial Aid Award
95 annotations
Standard entities 75
Docs / Pages 2
Hits 28
Misses 47
Type confusion 0
F1 (approx) 54%
View in Inspector →
Flight Itinerary
69 annotations
Standard entities 52
Docs / Pages 4
Hits 20
Misses 32
Type confusion 0
F1 (approx) 56%
View in Inspector →
Flight Itinerary Rev A
46 annotations
Standard entities 20
Docs / Pages 4
Hits 7
Misses 13
Type confusion 0
F1 (approx) 52%
View in Inspector →
Form 1040Es
47 annotations
Standard entities 44
Docs / Pages 2
Hits 11
Misses 33
Type confusion 0
F1 (approx) 40%
View in Inspector →
Franchise Agreement
21 annotations
Standard entities 72
Docs / Pages 10
Hits 41
Misses 31
Type confusion 0
F1 (approx) 73%
View in Inspector →
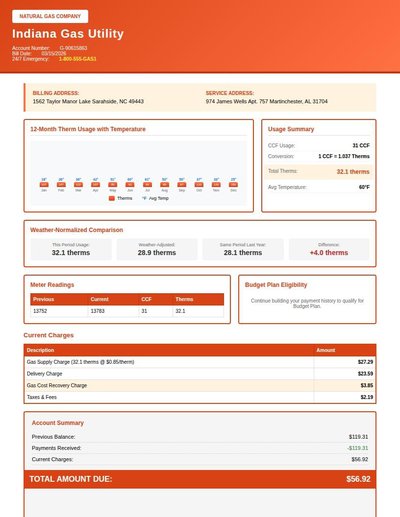
Gas Bill
40 annotations
Standard entities 44
Docs / Pages 4
Hits 34
Misses 10
Type confusion 0
F1 (approx) 87%
View in Inspector →
Grand Jury Indictment
21 annotations
Standard entities 49
Docs / Pages 5
Hits 28
Misses 21
Type confusion 0
F1 (approx) 73%
View in Inspector →
Hipaa Authorization
27 annotations
Standard entities 64
Docs / Pages 10
Hits 26
Misses 38
Type confusion 0
F1 (approx) 58%
View in Inspector →
Hipaa Breach Notification
25 annotations
Standard entities 50
Docs / Pages 6
Hits 28
Misses 22
Type confusion 0
F1 (approx) 72%
View in Inspector →
Hipaa Consent
20 annotations
Standard entities 22
Docs / Pages 6
Hits 16
Misses 6
Type confusion 0
F1 (approx) 84%
View in Inspector →
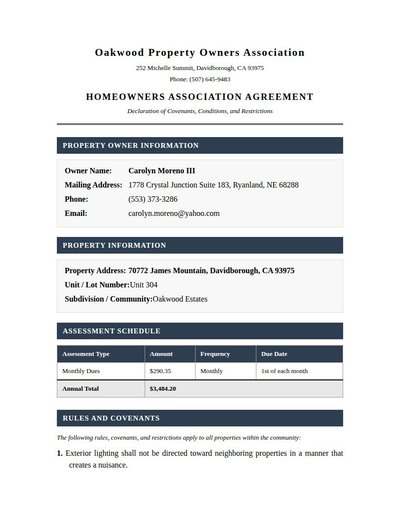
Hoa Agreement
36 annotations
Standard entities 35
Docs / Pages 6
Hits 23
Misses 12
Type confusion 0
F1 (approx) 79%
View in Inspector →
Hoa Violation Notice
30 annotations
Standard entities 60
Docs / Pages 4
Hits 33
Misses 27
Type confusion 0
F1 (approx) 71%
View in Inspector →
Home Inspection Report
42 annotations
Standard entities 48
Docs / Pages 8
Hits 19
Misses 29
Type confusion 0
F1 (approx) 57%
View in Inspector →
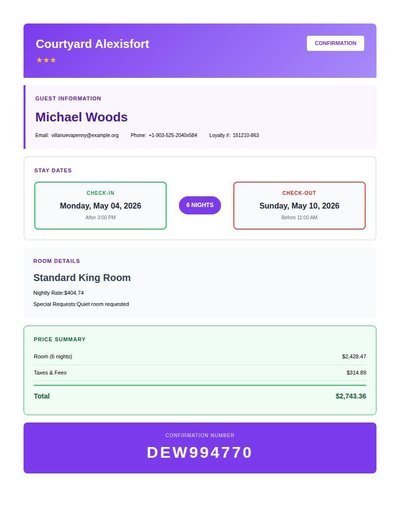
Hotel Booking
27 annotations
Standard entities 22
Docs / Pages 4
Hits 13
Misses 9
Type confusion 0
F1 (approx) 74%
View in Inspector →
Hotel Folio
119 annotations
Standard entities 76
Docs / Pages 3
Hits 26
Misses 50
Type confusion 0
F1 (approx) 51%
View in Inspector →
Hunting Fishing License
29 annotations
Standard entities 31
Docs / Pages 2
Hits 22
Misses 9
Type confusion 0
F1 (approx) 83%
View in Inspector →
I-9 Form
39 annotations
Standard entities 66
Docs / Pages 6
Hits 40
Misses 26
Type confusion 0
F1 (approx) 75%
View in Inspector →
Iep
66 annotations
Standard entities 66
Docs / Pages 6
Hits 36
Misses 30
Type confusion 0
F1 (approx) 71%
View in Inspector →
Insurance Claim
46 annotations
Standard entities 62
Docs / Pages 4
Hits 48
Misses 14
Type confusion 0
F1 (approx) 87%
View in Inspector →
Insurance Claim Form
44 annotations
Standard entities 52
Docs / Pages 6
Hits 41
Misses 11
Type confusion 0
F1 (approx) 88%
View in Inspector →
Insurance Policy
37 annotations
Standard entities 70
Docs / Pages 6
Hits 44
Misses 26
Type confusion 0
F1 (approx) 77%
View in Inspector →
Insurance Policy Rev A
81 annotations
Standard entities 120
Docs / Pages 4
Hits 28
Misses 92
Type confusion 0
F1 (approx) 38%
View in Inspector →
Insurance Policy Rev B
51 annotations
Standard entities 77
Docs / Pages 4
Hits 40
Misses 37
Type confusion 0
F1 (approx) 68%
View in Inspector →
Insurance Quote
48 annotations
Standard entities 48
Docs / Pages 6
Hits 36
Misses 12
Type confusion 0
F1 (approx) 86%
View in Inspector →
Investment Portfolio
42 annotations
Standard entities 377
Docs / Pages 6
Hits 44
Misses 333
Type confusion 0
F1 (approx) 21%
View in Inspector →
Investment Statement Rev A
46 annotations
Standard entities 86
Docs / Pages 4
Hits 34
Misses 52
Type confusion 0
F1 (approx) 57%
View in Inspector →
Invoice
119 annotations
Standard entities 111
Docs / Pages 4
Hits 20
Misses 91
Type confusion 0
F1 (approx) 31%
View in Inspector →
Invoice Rev A
70 annotations
Standard entities 86
Docs / Pages 4
Hits 30
Misses 56
Type confusion 0
F1 (approx) 52%
View in Inspector →
Invoice Rev B
100 annotations
Standard entities 96
Docs / Pages 4
Hits 20
Misses 76
Type confusion 0
F1 (approx) 34%
View in Inspector →
Irs Cp2000 Notice
73 annotations
Standard entities 80
Docs / Pages 2
Hits 33
Misses 47
Type confusion 0
F1 (approx) 58%
View in Inspector →
IRS Form
65 annotations
Standard entities 50
Docs / Pages 4
Hits 33
Misses 17
Type confusion 0
F1 (approx) 80%
View in Inspector →
IRS Form 1040
58 annotations
Standard entities 46
Docs / Pages 4
Hits 31
Misses 15
Type confusion 0
F1 (approx) 81%
View in Inspector →
IRS Tax Transcript
53 annotations
Standard entities 66
Docs / Pages 4
Hits 19
Misses 47
Type confusion 0
F1 (approx) 45%
View in Inspector →
IRS Transcript
58 annotations
Standard entities 42
Docs / Pages 4
Hits 13
Misses 29
Type confusion 0
F1 (approx) 47%
View in Inspector →
Jury Duty Summons
43 annotations
Standard entities 36
Docs / Pages 4
Hits 26
Misses 10
Type confusion 0
F1 (approx) 84%
View in Inspector →
Jury Verdict Form
45 annotations
Standard entities 77
Docs / Pages 4
Hits 14
Misses 63
Type confusion 0
F1 (approx) 31%
View in Inspector →
Lab Panel
124 annotations
Standard entities 128
Docs / Pages 4
Hits 16
Misses 112
Type confusion 0
F1 (approx) 22%
View in Inspector →
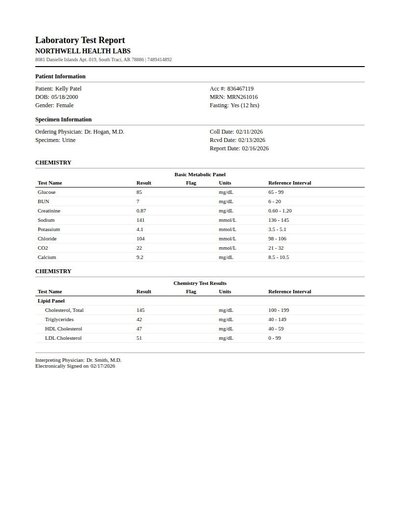
Lab Report
123 annotations
Standard entities 48
Docs / Pages 2
Hits 25
Misses 23
Type confusion 0
F1 (approx) 68%
View in Inspector →
Layout Example
17 annotations
Standard entities 14
Docs / Pages 4
Hits 6
Misses 8
Type confusion 0
F1 (approx) 60%
View in Inspector →
Lease Agreement
38 annotations
Standard entities 86
Docs / Pages 8
Hits 21
Misses 65
Type confusion 0
F1 (approx) 39%
View in Inspector →
Legal Pleading
36 annotations
Standard entities 51
Docs / Pages 9
Hits 25
Misses 26
Type confusion 0
F1 (approx) 66%
View in Inspector →
Living Will
10 annotations
Standard entities 38
Docs / Pages 6
Hits 28
Misses 10
Type confusion 0
F1 (approx) 85%
View in Inspector →
Llc Formation
24 annotations
Standard entities 28
Docs / Pages 4
Hits 20
Misses 8
Type confusion 0
F1 (approx) 83%
View in Inspector →
Loan Agreement
29 annotations
Standard entities 32
Docs / Pages 4
Hits 27
Misses 5
Type confusion 0
F1 (approx) 92%
View in Inspector →
Loan Application
41 annotations
Standard entities 24
Docs / Pages 2
Hits 19
Misses 5
Type confusion 0
F1 (approx) 88%
View in Inspector →
Loan Disclosure
71 annotations
Standard entities 49
Docs / Pages 4
Hits 31
Misses 18
Type confusion 0
F1 (approx) 78%
View in Inspector →
Loan Statement
42 annotations
Standard entities 50
Docs / Pages 4
Hits 38
Misses 12
Type confusion 0
F1 (approx) 86%
View in Inspector →
Loyalty Program Statement
86 annotations
Standard entities 68
Docs / Pages 4
Hits 21
Misses 47
Type confusion 0
F1 (approx) 47%
View in Inspector →
Marriage Certificate
46 annotations
Standard entities 40
Docs / Pages 2
Hits 20
Misses 20
Type confusion 0
F1 (approx) 67%
View in Inspector →
Mechanic Lien
61 annotations
Standard entities 83
Docs / Pages 4
Hits 45
Misses 38
Type confusion 0
F1 (approx) 70%
View in Inspector →
Medical Bill
95 annotations
Standard entities 83
Docs / Pages 4
Hits 46
Misses 37
Type confusion 0
F1 (approx) 71%
View in Inspector →
Medical Bill Rev A
140 annotations
Standard entities 112
Docs / Pages 4
Hits 30
Misses 82
Type confusion 0
F1 (approx) 42%
View in Inspector →
Medical Bill Rev B
41 annotations
Standard entities 46
Docs / Pages 4
Hits 43
Misses 3
Type confusion 0
F1 (approx) 97%
View in Inspector →
Medical Intake Form
52 annotations
Standard entities 48
Docs / Pages 4
Hits 40
Misses 8
Type confusion 0
F1 (approx) 91%
View in Inspector →
Medical Power Of Attorney
39 annotations
Standard entities 56
Docs / Pages 6
Hits 41
Misses 15
Type confusion 0
F1 (approx) 85%
View in Inspector →
Medical Prescription
82 annotations
Standard entities 48
Docs / Pages 2
Hits 43
Misses 5
Type confusion 0
F1 (approx) 95%
View in Inspector →
Medical Report
42 annotations
Standard entities 53
Docs / Pages 7
Hits 24
Misses 29
Type confusion 0
F1 (approx) 62%
View in Inspector →
Meeting Minutes
84 annotations
Standard entities 80
Docs / Pages 6
Hits 16
Misses 64
Type confusion 0
F1 (approx) 33%
View in Inspector →
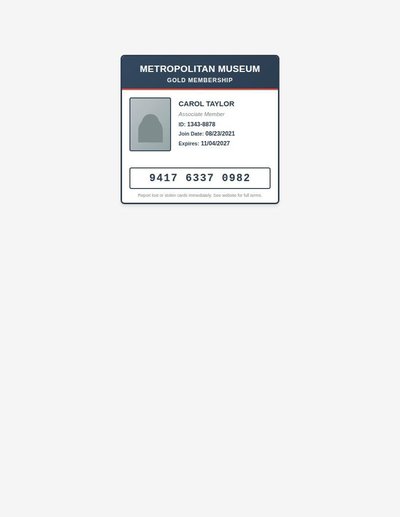
Membership Card
12 annotations
Standard entities 12
Docs / Pages 2
Hits 10
Misses 2
Type confusion 0
F1 (approx) 91%
View in Inspector →
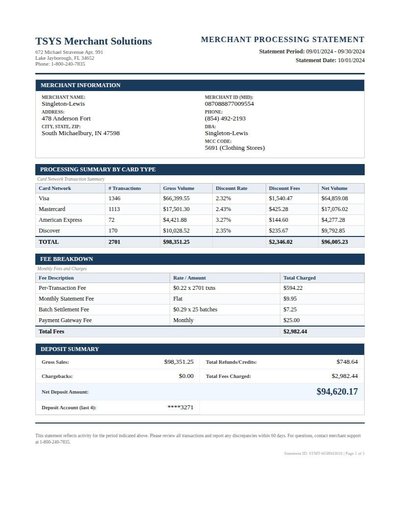
Merchant Statement
130 annotations
Standard entities 102
Docs / Pages 2
Hits 36
Misses 66
Type confusion 0
F1 (approx) 52%
View in Inspector →
MSDS
37 annotations
Standard entities 32
Docs / Pages 16
Hits 16
Misses 16
Type confusion 0
F1 (approx) 67%
View in Inspector →
NDA
22 annotations
Standard entities 84
Docs / Pages 14
Hits 32
Misses 52
Type confusion 0
F1 (approx) 55%
View in Inspector →
Notarized Affidavit
25 annotations
Standard entities 24
Docs / Pages 6
Hits 16
Misses 8
Type confusion 0
F1 (approx) 80%
View in Inspector →
Offer Letter
28 annotations
Standard entities 43
Docs / Pages 4
Hits 30
Misses 13
Type confusion 0
F1 (approx) 82%
View in Inspector →
Order Confirmation
96 annotations
Standard entities 66
Docs / Pages 4
Hits 36
Misses 30
Type confusion 0
F1 (approx) 71%
View in Inspector →
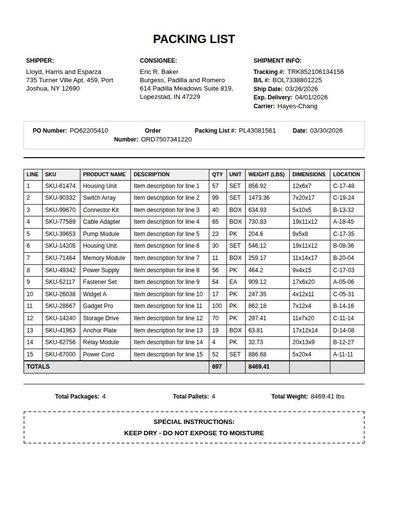
Packing List
190 annotations
Standard entities 84
Docs / Pages 3
Hits 27
Misses 57
Type confusion 0
F1 (approx) 49%
View in Inspector →
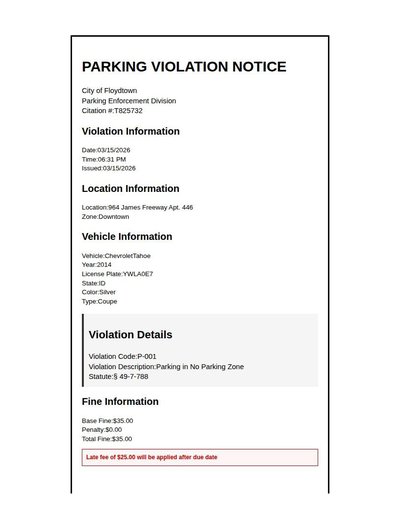
Parking Ticket
47 annotations
Standard entities 42
Docs / Pages 4
Hits 27
Misses 15
Type confusion 0
F1 (approx) 78%
View in Inspector →
Partnership Agreement
6 annotations
Standard entities 18
Docs / Pages 6
Hits 16
Misses 2
Type confusion 0
F1 (approx) 94%
View in Inspector →
Passport
21 annotations
Standard entities 16
Docs / Pages 2
Hits 8
Misses 8
Type confusion 0
F1 (approx) 67%
View in Inspector →
Passport Renewal
75 annotations
Standard entities 50
Docs / Pages 4
Hits 42
Misses 8
Type confusion 0
F1 (approx) 91%
View in Inspector →
Passport Rev A
22 annotations
Standard entities 18
Docs / Pages 2
Hits 10
Misses 8
Type confusion 0
F1 (approx) 71%
View in Inspector →
Passport Rev B
29 annotations
Standard entities 24
Docs / Pages 2
Hits 6
Misses 18
Type confusion 0
F1 (approx) 40%
View in Inspector →
Patent
56 annotations
Standard entities 134
Docs / Pages 9
Hits 37
Misses 97
Type confusion 0
F1 (approx) 43%
View in Inspector →
Patent Application
30 annotations
Standard entities 68
Docs / Pages 11
Hits 32
Misses 36
Type confusion 0
F1 (approx) 64%
View in Inspector →
Pay Stub
98 annotations
Standard entities 71
Docs / Pages 2
Hits 23
Misses 48
Type confusion 0
F1 (approx) 49%
View in Inspector →
Payroll Slip
101 annotations
Standard entities 68
Docs / Pages 4
Hits 19
Misses 49
Type confusion 0
F1 (approx) 44%
View in Inspector →
Performance Review
69 annotations
Standard entities 91
Docs / Pages 4
Hits 14
Misses 77
Type confusion 0
F1 (approx) 27%
View in Inspector →
Pet License
45 annotations
Standard entities 40
Docs / Pages 2
Hits 28
Misses 12
Type confusion 0
F1 (approx) 82%
View in Inspector →
Police Crash Report
51 annotations
Standard entities 68
Docs / Pages 6
Hits 46
Misses 22
Type confusion 0
F1 (approx) 81%
View in Inspector →
Power Of Attorney
21 annotations
Standard entities 44
Docs / Pages 8
Hits 35
Misses 9
Type confusion 0
F1 (approx) 89%
View in Inspector →
Prescription
38 annotations
Standard entities 44
Docs / Pages 4
Hits 27
Misses 17
Type confusion 0
F1 (approx) 76%
View in Inspector →
Presentence Investigation
44 annotations
Standard entities 54
Docs / Pages 6
Hits 31
Misses 23
Type confusion 0
F1 (approx) 73%
View in Inspector →
Probation Report
51 annotations
Standard entities 50
Docs / Pages 6
Hits 36
Misses 14
Type confusion 0
F1 (approx) 84%
View in Inspector →
Professional License
19 annotations
Standard entities 24
Docs / Pages 2
Hits 17
Misses 7
Type confusion 0
F1 (approx) 83%
View in Inspector →
Promissory Note
36 annotations
Standard entities 42
Docs / Pages 6
Hits 36
Misses 6
Type confusion 0
F1 (approx) 92%
View in Inspector →
Promo Note
31 annotations
Standard entities 32
Docs / Pages 6
Hits 21
Misses 11
Type confusion 0
F1 (approx) 79%
View in Inspector →
Property Appraisal
100 annotations
Standard entities 74
Docs / Pages 4
Hits 38
Misses 36
Type confusion 0
F1 (approx) 68%
View in Inspector →
Property Assessment Notice
58 annotations
Standard entities 66
Docs / Pages 2
Hits 22
Misses 44
Type confusion 0
F1 (approx) 50%
View in Inspector →
Property Listing
37 annotations
Standard entities 32
Docs / Pages 4
Hits 24
Misses 8
Type confusion 0
F1 (approx) 86%
View in Inspector →
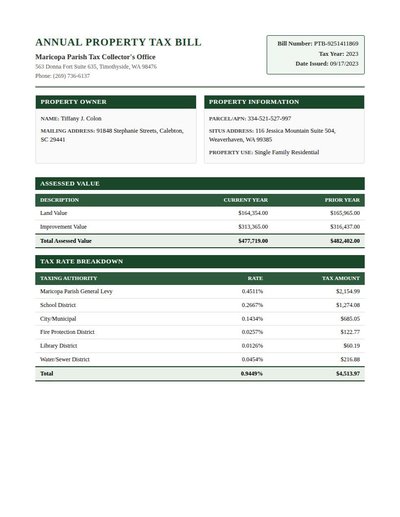
Property Tax Bill
74 annotations
Standard entities 64
Docs / Pages 4
Hits 29
Misses 35
Type confusion 0
F1 (approx) 62%
View in Inspector →
Purchase Order
102 annotations
Standard entities 92
Docs / Pages 4
Hits 22
Misses 70
Type confusion 0
F1 (approx) 39%
View in Inspector →
Quitclaim Deed
31 annotations
Standard entities 44
Docs / Pages 4
Hits 24
Misses 20
Type confusion 0
F1 (approx) 71%
View in Inspector →
Radiology Report
39 annotations
Standard entities 32
Docs / Pages 4
Hits 30
Misses 2
Type confusion 0
F1 (approx) 97%
View in Inspector →
Referral Letter
38 annotations
Standard entities 40
Docs / Pages 4
Hits 36
Misses 4
Type confusion 0
F1 (approx) 95%
View in Inspector →
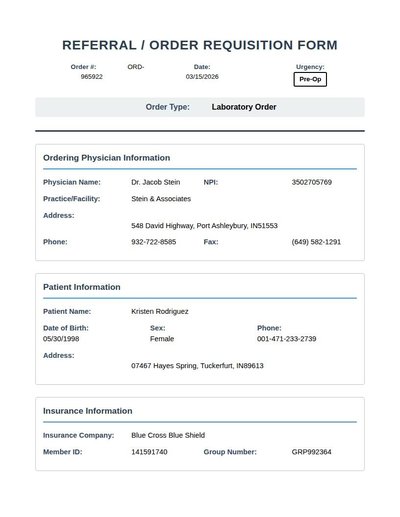
Referral Order Template
48 annotations
Standard entities 56
Docs / Pages 4
Hits 26
Misses 30
Type confusion 0
F1 (approx) 63%
View in Inspector →
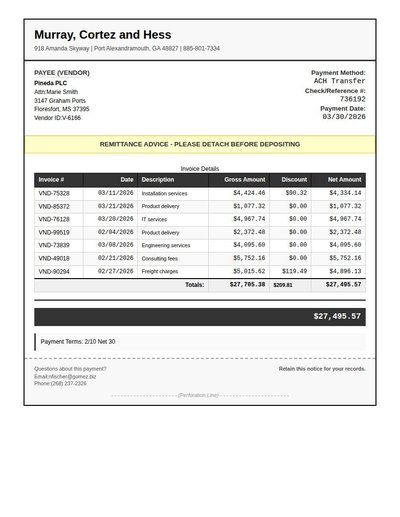
Remittance Advice
115 annotations
Standard entities 82
Docs / Pages 2
Hits 25
Misses 57
Type confusion 0
F1 (approx) 47%
View in Inspector →
Rental Agreement
34 annotations
Standard entities 36
Docs / Pages 6
Hits 32
Misses 4
Type confusion 0
F1 (approx) 94%
View in Inspector →
Rental Application
49 annotations
Standard entities 78
Docs / Pages 6
Hits 51
Misses 27
Type confusion 0
F1 (approx) 79%
View in Inspector →
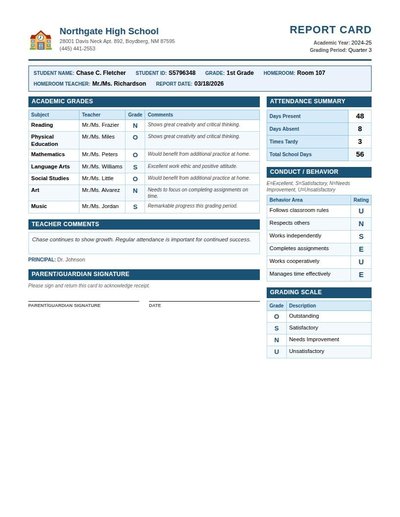
Report Card
88 annotations
Standard entities 30
Docs / Pages 2
Hits 16
Misses 14
Type confusion 0
F1 (approx) 70%
View in Inspector →
Restaurant Receipt
77 annotations
Standard entities 71
Docs / Pages 2
Hits 20
Misses 51
Type confusion 0
F1 (approx) 44%
View in Inspector →
Restaurant Receipt Rev A
46 annotations
Standard entities 36
Docs / Pages 2
Hits 19
Misses 17
Type confusion 0
F1 (approx) 69%
View in Inspector →
Restaurant Receipt Rev B
31 annotations
Standard entities 41
Docs / Pages 5
Hits 18
Misses 23
Type confusion 0
F1 (approx) 61%
View in Inspector →
Restraining Order
40 annotations
Standard entities 56
Docs / Pages 4
Hits 30
Misses 26
Type confusion 0
F1 (approx) 70%
View in Inspector →
Resume
36 annotations
Standard entities 28
Docs / Pages 4
Hits 20
Misses 8
Type confusion 0
F1 (approx) 83%
View in Inspector →
Resume Rev A
54 annotations
Standard entities 32
Docs / Pages 3
Hits 24
Misses 8
Type confusion 0
F1 (approx) 86%
View in Inspector →
Resume Rev B
46 annotations
Standard entities 32
Docs / Pages 3
Hits 23
Misses 9
Type confusion 0
F1 (approx) 84%
View in Inspector →
Resume Rev C
50 annotations
Standard entities 35
Docs / Pages 3
Hits 25
Misses 10
Type confusion 0
F1 (approx) 83%
View in Inspector →
Retail Receipt
71 annotations
Standard entities 59
Docs / Pages 2
Hits 29
Misses 30
Type confusion 0
F1 (approx) 66%
View in Inspector →
Retirement Statement
55 annotations
Standard entities 64
Docs / Pages 4
Hits 30
Misses 34
Type confusion 0
F1 (approx) 64%
View in Inspector →
Safe Deposit Agreement
68 annotations
Standard entities 66
Docs / Pages 4
Hits 42
Misses 24
Type confusion 0
F1 (approx) 78%
View in Inspector →
Scalable Document
0 annotations
Standard entities 0
Docs / Pages 17
Hits 0
Misses 0
Type confusion 0
F1 (approx) —
View in Inspector →
Schedule K-1
86 annotations
Standard entities 73
Docs / Pages 2
Hits 46
Misses 27
Type confusion 0
F1 (approx) 77%
View in Inspector →
Schedule K-1 (1065)
33 annotations
Standard entities 110
Docs / Pages 6
Hits 66
Misses 44
Type confusion 0
F1 (approx) 75%
View in Inspector →
Scholarship Award
28 annotations
Standard entities 50
Docs / Pages 4
Hits 27
Misses 23
Type confusion 0
F1 (approx) 70%
View in Inspector →
Search Warrant
24 annotations
Standard entities 34
Docs / Pages 4
Hits 27
Misses 7
Type confusion 0
F1 (approx) 89%
View in Inspector →
Service Agreement
32 annotations
Standard entities 36
Docs / Pages 6
Hits 25
Misses 11
Type confusion 0
F1 (approx) 82%
View in Inspector →
Service Level Agreement
28 annotations
Standard entities 26
Docs / Pages 6
Hits 16
Misses 10
Type confusion 0
F1 (approx) 76%
View in Inspector →
Settlement Agreement
19 annotations
Standard entities 58
Docs / Pages 12
Hits 38
Misses 20
Type confusion 0
F1 (approx) 79%
View in Inspector →
Shipping Label
34 annotations
Standard entities 26
Docs / Pages 2
Hits 22
Misses 4
Type confusion 0
F1 (approx) 92%
View in Inspector →
Shipping Label Rev A
28 annotations
Standard entities 27
Docs / Pages 2
Hits 17
Misses 10
Type confusion 0
F1 (approx) 77%
View in Inspector →
Shipping Label Rev B
27 annotations
Standard entities 28
Docs / Pages 2
Hits 19
Misses 9
Type confusion 0
F1 (approx) 81%
View in Inspector →
Site Daily Log
36 annotations
Standard entities 90
Docs / Pages 8
Hits 24
Misses 66
Type confusion 0
F1 (approx) 42%
View in Inspector →
Social Security Card
18 annotations
Standard entities 12
Docs / Pages 2
Hits 6
Misses 6
Type confusion 0
F1 (approx) 67%
View in Inspector →
Ss Benefit Letter
64 annotations
Standard entities 59
Docs / Pages 4
Hits 56
Misses 3
Type confusion 0
F1 (approx) 97%
View in Inspector →
Ssa1099
82 annotations
Standard entities 58
Docs / Pages 4
Hits 21
Misses 37
Type confusion 0
F1 (approx) 53%
View in Inspector →
Stock Certificate
35 annotations
Standard entities 30
Docs / Pages 2
Hits 22
Misses 8
Type confusion 0
F1 (approx) 85%
View in Inspector →
Storage Unit Lease
65 annotations
Standard entities 64
Docs / Pages 2
Hits 31
Misses 33
Type confusion 0
F1 (approx) 65%
View in Inspector →
Subpoena Duces Tecum
21 annotations
Standard entities 35
Docs / Pages 6
Hits 26
Misses 9
Type confusion 0
F1 (approx) 85%
View in Inspector →
Surgical Consent
14 annotations
Standard entities 39
Docs / Pages 10
Hits 12
Misses 27
Type confusion 0
F1 (approx) 47%
View in Inspector →
Surgical Op Note
54 annotations
Standard entities 45
Docs / Pages 4
Hits 38
Misses 7
Type confusion 0
F1 (approx) 92%
View in Inspector →
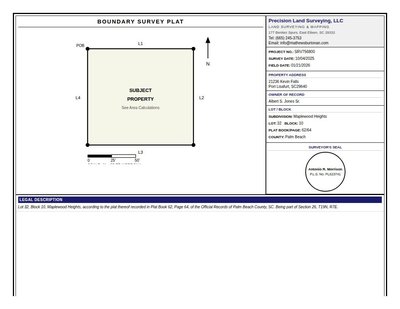
Survey Plat
53 annotations
Standard entities 42
Docs / Pages 4
Hits 24
Misses 18
Type confusion 0
F1 (approx) 73%
View in Inspector →
Table Example
124 annotations
Standard entities 104
Docs / Pages 2
Hits 8
Misses 96
Type confusion 0
F1 (approx) 14%
View in Inspector →
Tax 1098
49 annotations
Standard entities 39
Docs / Pages 2
Hits 29
Misses 10
Type confusion 0
F1 (approx) 85%
View in Inspector →
Tax 1099
39 annotations
Standard entities 60
Docs / Pages 4
Hits 33
Misses 27
Type confusion 0
F1 (approx) 71%
View in Inspector →
Tax Return
3 annotations
Standard entities 28
Docs / Pages 8
Hits 16
Misses 12
Type confusion 0
F1 (approx) 73%
View in Inspector →
Termite Inspection
84 annotations
Standard entities 44
Docs / Pages 4
Hits 29
Misses 15
Type confusion 0
F1 (approx) 79%
View in Inspector →
Test Showcase
19 annotations
Standard entities 350
Docs / Pages 41
Hits 104
Misses 246
Type confusion 0
F1 (approx) 46%
View in Inspector →
Timeshare Contract
34 annotations
Standard entities 92
Docs / Pages 6
Hits 47
Misses 45
Type confusion 0
F1 (approx) 68%
View in Inspector →
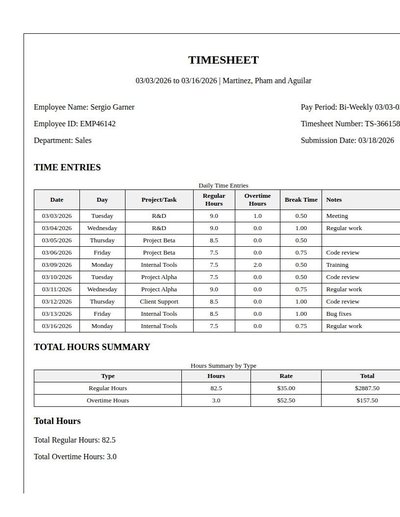
Timesheet
162 annotations
Standard entities 124
Docs / Pages 4
Hits 29
Misses 95
Type confusion 0
F1 (approx) 38%
View in Inspector →
Title Commitment
24 annotations
Standard entities 24
Docs / Pages 6
Hits 24
Misses 0
Type confusion 0
F1 (approx) 100%
View in Inspector →
Trademark Registration
44 annotations
Standard entities 50
Docs / Pages 6
Hits 27
Misses 23
Type confusion 0
F1 (approx) 70%
View in Inspector →
Traffic Citation
45 annotations
Standard entities 50
Docs / Pages 2
Hits 26
Misses 24
Type confusion 0
F1 (approx) 68%
View in Inspector →
UB-04 Hospital Claims
58 annotations
Standard entities 138
Docs / Pages 6
Hits 66
Misses 72
Type confusion 0
F1 (approx) 65%
View in Inspector →
Ucc1 Financing Statement
22 annotations
Standard entities 45
Docs / Pages 2
Hits 25
Misses 20
Type confusion 0
F1 (approx) 71%
View in Inspector →
Unemployment Benefit
77 annotations
Standard entities 54
Docs / Pages 4
Hits 46
Misses 8
Type confusion 0
F1 (approx) 92%
View in Inspector →
Universal Form
38 annotations
Standard entities 32
Docs / Pages 4
Hits 9
Misses 23
Type confusion 0
F1 (approx) 44%
View in Inspector →
USPTO Document
31 annotations
Standard entities 58
Docs / Pages 8
Hits 24
Misses 34
Type confusion 0
F1 (approx) 59%
View in Inspector →
Utility Bill
56 annotations
Standard entities 48
Docs / Pages 4
Hits 23
Misses 25
Type confusion 0
F1 (approx) 65%
View in Inspector →
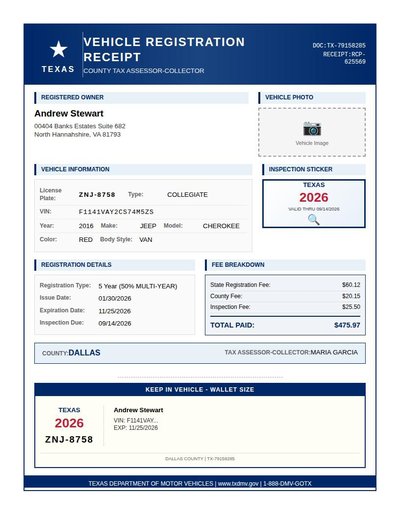
Vehicle Registration
47 annotations
Standard entities 36
Docs / Pages 4
Hits 26
Misses 10
Type confusion 0
F1 (approx) 84%
View in Inspector →
Vehicle Registration Rev A
12 annotations
Standard entities 16
Docs / Pages 2
Hits 14
Misses 2
Type confusion 0
F1 (approx) 93%
View in Inspector →
Vehicle Registration Rev B
15 annotations
Standard entities 20
Docs / Pages 4
Hits 12
Misses 8
Type confusion 0
F1 (approx) 75%
View in Inspector →
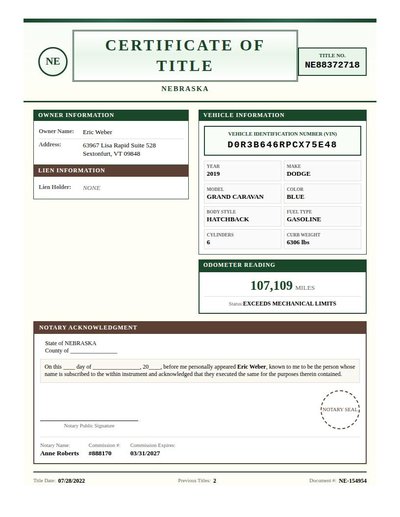
Vehicle Title
14 annotations
Standard entities 20
Docs / Pages 4
Hits 11
Misses 9
Type confusion 0
F1 (approx) 71%
View in Inspector →
Visa
0 annotations
Standard entities 80
Docs / Pages 10
Hits 59
Misses 21
Type confusion 0
F1 (approx) 85%
View in Inspector →
Voter Registration
28 annotations
Standard entities 26
Docs / Pages 4
Hits 18
Misses 8
Type confusion 0
F1 (approx) 82%
View in Inspector →
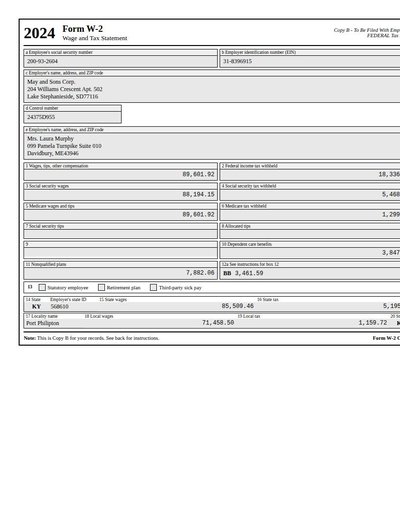
W-2 Form
83 annotations
Standard entities 90
Docs / Pages 2
Hits 4
Misses 86
Type confusion 0
F1 (approx) 9%
View in Inspector →
W2 Rev A
65 annotations
Standard entities 58
Docs / Pages 2
Hits 24
Misses 34
Type confusion 0
F1 (approx) 59%
View in Inspector →
W2 Rev B
81 annotations
Standard entities 71
Docs / Pages 2
Hits 23
Misses 48
Type confusion 0
F1 (approx) 49%
View in Inspector →
W-4 Form
40 annotations
Standard entities 44
Docs / Pages 4
Hits 18
Misses 26
Type confusion 0
F1 (approx) 58%
View in Inspector →
W4 Rev A
44 annotations
Standard entities 33
Docs / Pages 2
Hits 13
Misses 20
Type confusion 0
F1 (approx) 57%
View in Inspector →
W-9 Form
28 annotations
Standard entities 26
Docs / Pages 4
Hits 6
Misses 20
Type confusion 0
F1 (approx) 38%
View in Inspector →
Warranty
45 annotations
Standard entities 36
Docs / Pages 6
Hits 28
Misses 8
Type confusion 0
F1 (approx) 88%
View in Inspector →
Warranty Claim
47 annotations
Standard entities 46
Docs / Pages 6
Hits 39
Misses 7
Type confusion 0
F1 (approx) 92%
View in Inspector →
Warranty Deed
35 annotations
Standard entities 64
Docs / Pages 4
Hits 28
Misses 36
Type confusion 0
F1 (approx) 61%
View in Inspector →
Water Bill
41 annotations
Standard entities 52
Docs / Pages 4
Hits 40
Misses 12
Type confusion 0
F1 (approx) 87%
View in Inspector →
Will Trust
59 annotations
Standard entities 76
Docs / Pages 4
Hits 44
Misses 32
Type confusion 0
F1 (approx) 73%
View in Inspector →
Wire Transfer
37 annotations
Standard entities 36
Docs / Pages 4
Hits 24
Misses 12
Type confusion 0
F1 (approx) 80%
View in Inspector →
Work Order
63 annotations
Standard entities 53
Docs / Pages 4
Hits 27
Misses 26
Type confusion 0
F1 (approx) 68%
View in Inspector →
Workers Comp
72 annotations
Standard entities 74
Docs / Pages 4
Hits 47
Misses 27
Type confusion 0
F1 (approx) 78%
View in Inspector →
Baseline: DeepSeek-OCR-2 + Qwen3-8B
OCR via DeepSeek-OCR-2 (vision model), NER via Qwen3-8B (prompted, zero-shot). No fine-tuning.
Entity Type TP FP FN Precision Recall F1 F1
PHONE 274 36 23 0.884 0.923 0.903 PERSON 615 119 108 0.838 0.851 0.844 DATE 1,256 318 497 0.798 0.717 0.755 ORG 510 198 226 0.720 0.693 0.706 ID 894 255 653 0.778 0.578 0.663 AMOUNT 1,938 644 1,843 0.751 0.513 0.609 ADDRESS 358 550 127 0.394 0.738 0.514